
Last week, I wrote a blog post about collecting data using Tweepy in Python. Like usual, I decided to recreate my work in R, so that I can compare my experience using different analytical tools. I will walk you through what I did, but I assume that you already have Rstudio installed. If not, and you wish to follow along, here’s a link to a good resource that explains how to download and install Rstudio.
Begin by loading the following libraries–download them if you don’t have them already installed.
#To download:
#install.packages(c("twitteR", "purrr", "dplyr", "stringr"),dependencies=TRUE)
library(twitteR)
library(purrr)
suppressMessages(library(dplyr))
library(stringr)
Next, initiate the OAuth protocol. This of course assumes that you have registered your Twitter app. If not, here’s a link that explains how to do this.
api_key <- "your_consumer_api_key"
api_secret <-"your_consumer_api_secret"
token <- "your_access_token"
token_secret <- "your_access_secret"
setup_twitter_oauth(api_key, api_secret, token, token_secret)
Now you can use the package twitteR to collect the information that you want. For example, #rstats or #rladies <–great hashtags to follow on Twitter, btw 😉
tw = searchTwitter('#rladies + #rstats', n = 20)
which will return a list of (20) tweets that contain the two search terms that I specified:

*If you want more than 20 tweets, simply increase the number following n=
Alternatively, you can collect data on a specific user. For example, I am going to collect tweets from this awesome R-Lady, @Lego_RLady:
Again, using the twitteR package, type the following:
LegoRLady <- getUser("LEGO_RLady") #for info on the user
RLady_tweets<-userTimeline("LEGO_RLady",n=30,retryOnRateLimit=120) #to get tweets
tweets.df<-twListToDF(RLady_tweets) #turn into data frame
write.csv(tweets.df, "Rlady_tweets.csv", row.names = FALSE) #export to Excel
Luckily, she only has 27 tweets total. If you are collecting tweets from a user that has been on Twitter for longer, you’ll likely have to use a loop to continue collecting every tweet because of the rate limit. If you export to Excel, you should see something like this:
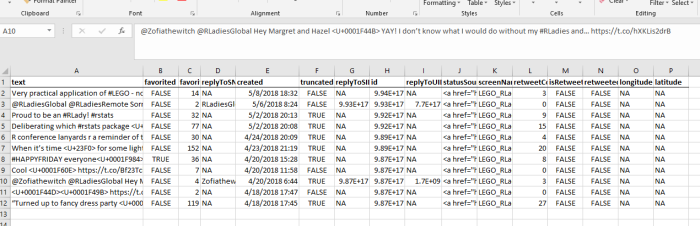
*Note: I bolded the column names and created the border to help distinguish the data
If you’re interested in the retweets and replies to @LEGO_RLady, then you can search for that specifically. To limit the amount of data, let’s limit it to any replies since the following tweet:
target_tweet<-"991771358634889222"
atRLady <- searchTwitter("@LEGO_RLady",
sinceID=target_tweet, n=25, retryOnRateLimit = 20)
atRLady.df<-twListToDF(atRLady)
The atRLady.df data frame should look like this:
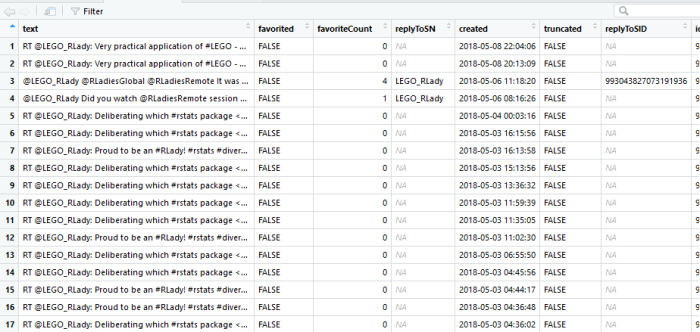
There’s much more data if you scroll right. You should have 16 variables total.
Sometimes there are characters in the tweet that result in errors. To make sure that the tweet is in plain text, you can do the following:
replies <- unlist(atRLady) #make sure to use the list and not the data frame
#helper function to remove characters:
clean_tweets <- function (tweet_list) {
lapply(tweet_list, function (x) {
x <- x$getText() # get text alone
x <- gsub("&", "", x) # rm ampersands
x <- gsub("(f|ht)(tp)(s?)(://)(.*)[.|/](.*) ?", "", x) # rm links
x <- gsub("#\\w+", "", x) # rm hashtags
x <- gsub("@\\w+", "", x) # rm usernames
x <- iconv(x, "latin1", "ASCII", sub="") # rm emojis
x <- gsub("[[:punct:]]", "", x) # rm punctuation
x <- gsub("[[:digit:]]", "", x) # rm numbers
x <- gsub("[ \t]{2}", " ", x) # rm tabs
x <- gsub("\\s+", " ", x) # rm extra spaces
x <- trimws(x) # rm leading and trailing white space
x <- tolower(x) # convert to lower case
})
}
tweets_clean <- unlist(clean_tweets(replies))
# If you want to rebombine the text with the metadata (user, time, favorites, retweets)
tweet_data <- data.frame(text=tweets_clean)
tweet_data <- tweet_data[tweet_data$text != "",]
tweet_data<-data.frame(tweet_data)
tweet_data$user <-atRLady.df$screenName
tweet_data$time <- atRLady.df$created
tweet_data$favorites <- atRLady.df$favoriteCount
tweet_data$retweets <- atRLady.df$retweetCount
tweet_data$time_bin <- cut.POSIXt(tweet_data$time, breaks="3 hours", labels = FALSE)
tweet_data$isRetweet <- atRLady.df$isRetweet
You can pull other information from the original data frame as well, but I don’t find that information very helpful since it is usually NA (e.g., latitude and longitude). The final data frame should look like this:
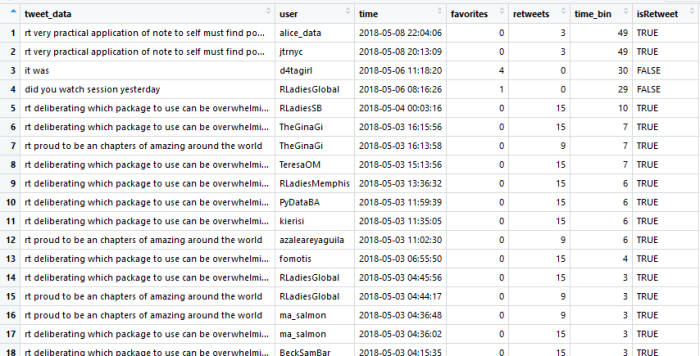
Now you can analyze it. For example, you can graph retweets for each reply
library(ggplot2)
ggplot(data = tweet_data, aes(x = retweets)) +
geom_bar(aes(fill = ..count..)) +
theme(legend.position = "none") +
xlab("Retweets") +
scale_fill_gradient(low = "midnightblue", high = "aquamarine4")
dev.copy(png,'myplot.png')
dev.off()
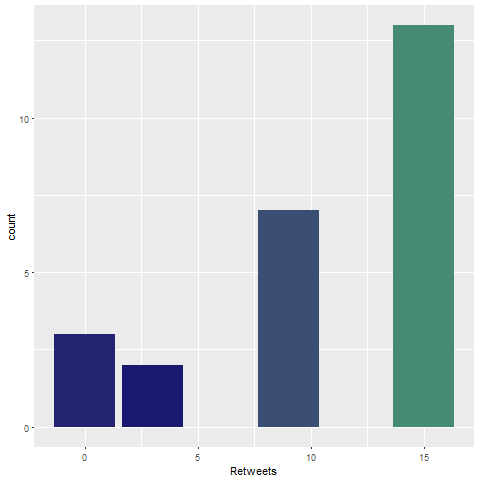
If you have more data, you can conduct a sentiment analysis of all the words in the text of the tweets or create a wordcloud (example below)

Overall, using R to collect data from Twitter was really easy. Honestly, it was pretty easy to do in Python too. However, I must say that the R community is slightly better when it comes to sharing resources and blogs that make it easy for beginners to follow what they’ve done. I really love the open source community and I’m excited that I am apart of this movement!
PS- I forgot to announce that I am officially an R-Lady (see directory)! To all my fellow lady friends, I encourage you to join!
